http://www.scientificcomputing.com/news/2014/05/neural-networks-imitate-intelligence-biological-brains
http://www.businessinsider.com/the-man-who-is-trying-to-make-humans-immortal-2014-5
http://stackoverflow.com/questions/8107994/artificial-neural-network-tutorial-with-step-by-step-code-implementation
http://www.mind.ilstu.edu/curriculum/modOverview.php?modGUI=212
Monday, May 19, 2014
Saturday, April 26, 2014
Genetic Algorithms and the Traveling Salesman Problem
http://www.math.hmc.edu/seniorthesis/archives/2001/kbryant/kbryant-2001-thesis.pdf
http://www.theprojectspot.com/tutorial-post/applying-a-genetic-algorithm-to-the-travelling-salesman-problem/5
http://www.lalena.com/AI/Tsp/
http://www.theprojectspot.com/tutorial-post/applying-a-genetic-algorithm-to-the-travelling-salesman-problem/5
http://www.lalena.com/AI/Tsp/
Thursday, April 24, 2014
orthogonal array
A very good tutorial
http://cse.unl.edu/~citportal/orthogonalArrayTutorial.php?start=1
http://www.51testing.com/ddimg/uploadsoft/20090113/OATSEN.pdf
http://cse.unl.edu/~citportal/orthogonalArrayTutorial.php?start=1
http://www.51testing.com/ddimg/uploadsoft/20090113/OATSEN.pdf
Friday, April 18, 2014
hill climbing vs best first search
They are quite similar. The difference is that best-first search considers all paths from the start node to the end node, whereas steepest ascent hill climbing only remembers one path during the search.
For example, say we have a graph like
start ---- A ---- B ---- end
\ /
------\ /---------
\ /
C
where each edge has the same weight: ignore my crappy ASCII art skills :). Also suppose that in our heuristic function, A is considered as closer to the end than C. (This could still be an admissible heuristic– it just underestimates the true distance of A.)
Then steepest-ascent hill climbing would choose A first (because it has the lowest heuristic value), then B (because its heuristic value is lower than the start node's), and then the end node.
A best-first search, on the other hand, would
- Add A and C to the open list.
- Take A, the best value, off the open list, and add B. Then OPEN = {B, C}.
- Take the best node off the open list (either B or C, more on that in a second), and add its successor, the goal state.
- Take the goal state off the open list and return the path that got there.
The choice of B or C in step 3 depends on exactly the best-first search algorithm you're using. A* would evaluate the node as the cost to get there plus the estimate of the cost to get to the end, in which case C would win (and in fact, with an admissible heuristic, A* is guaranteed to always get you the optimal path). A "greedy best-first search" would choose between the two options arbitrarily. In any case, the search maintains a list of possible places to go from rather than a single one.
Is it clearer how the two are different now?
Evaluation by Hill-climbing
Evaluation by Hill-climbing: Getting the right move by solving micro-problems:
Author: Jeff Rollason
Computers play games using many techniques, but a key one frequently used is hill climbing. The premise of this is that a game may not be solvable to a solution in a single move evaluation (as is possible for games such as Tic-tac-toe), so that the evaluation has to assess intermediate sub-win states that will eventually lead the player to a win. The game engine therefore aims with each move to reach the position nearest to a win (solving a partial solution). Having got there it repeats the same process selecting moves until it reaches the win state.
In evaluation terms, if a win equates to 10 points, where you start with zero points, then the game engine will progressively make moves that gradually change the value of the position from 0 to 10.
This process can be represented by an analogy of a hill-walker looking for the summit. In the diagram below the hill-walker can choose to move in multiple directions, seeking the summit (10).
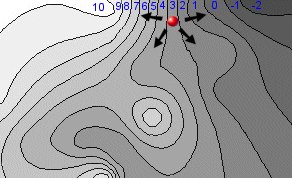
In this instance we can assume that the hill-walker cannot see very far, so can only assess the gradient immediately around his position. In this instance the hill-walker can choose from a selection of directions and choose to walk to the left, which offers the most elevated new position. In this case from "3" to "4". The hill-walker moves and repeats the process and clearly, in a few moves, will reach the summit "10" on the map.
The hill here represents the evaluation function for the program which returns a value that tells it how close it is to a win.
In an ideal world, with an ideal evaluation function, the hill would be very simple, offering a single summit with a uniform continuous gradient (a huge cone, in fact)). Given this the program could easily reach the summit (win). However in the diagram above this is clearly not the case:
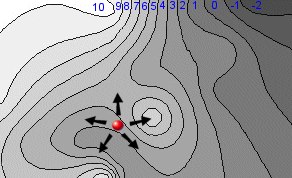
If the hill-walker starts from the different position shown above, he will clearly reach a lower local maxima, a "false summit". From there he cannot reach the final summit.
This is the start of a number of possible problems. In this instance the hill-walker can overcome the problem by looking further ahead. In evaluation terms this means performing a tree search such that a sequence of predicted moves allows the hill-walker to find the real more distant summit. In this case a deeper search (prediction of many successive moves), could solve this problem.
However the situation above still implies a relatively regular and reliable evaluation gradient. This is not generally the case:
Evaluation potholes
The nice smooth evaluation gradient above assumes some well-behaved evaluation that delivers a smooth analogue value. In practice evaluations are usually a combination of terms that are simply added together. If each term is independent, then this can be managed, but often as not they are linked. A typical problem arises when assessing latent and actual features. The following chess position is such an example:

In this position an evaluation feature might be a credit for a rook being able to occupy an open file. The rook at e8 has the option of occupying d8, so gains this credit. However if the rook actually moves to d8, it will lose this credit and instead get evaluation credit for attacking the squares d5, d6 and d7 and the pawn on d4. In this case a credit of (say) 8 points for the ability to occupy the open file may be replaced by 30 points for actually occupying the file. This would then not cause a problem, as the program could progress from opportunity to occupying the file by simply climbing the evaluation gradient.
However this might not be so. The actual value of occupying the file might be less than expected, so the opportunity to occupy the file may be more than actually occupying it. This is an evaluation pothole, and may make the program stop progressing as it prefers the opportunity to occupy the file to actually occupying it. In consequence the program may well move the rook from this file, simply to gain the opportunity to do it, rather than actually do it.
This is a simple case, but sometimes these potholes can be very deep! Also the situation is actually quite common. The symptoms of this are hard to read, as the program may still progress, but may be confused as a tree search endlessly experiments with trading feature opportunities with the actual feature. This may make the program dither or simply slow up the tree search.
Fixing the Pot Holes
The example above was quite simple, but this gradient failure may be the product of multiple combined terms. You may be trading latent and actual threats, but you may also be simply trading different features. The only way to address this is to test your program, by displaying the net value of moves from given positions. This can be run for a whole game.
The programmer then needs to carefully examine this list of moves and the net change in value to detect anomalies. You may find that a move, which is obviously beneficial, actually has a negative net score. Once found, you need to display all the evaluation terms used to derive this to detect why the move is apparently bad and correct the anomaly.
This requires a lot of patient work, but the benefit is a program that will not seem to habitually get lost or seemingly hesitate. Of course evaluation functions change with tuning, so this is a process you may need to return to many times.
Jumping over potholes
Of course, regardless of the scrutiny you may apply, there will always be potholes, so you need other methods to avoid these.
1. Tree Search
Of course, if you predict many moves in advance, you can find the way in and way out of potholes. However this is not a substitute for fixing them! Potholes create hesitant play and slow up tree search as the search gets confused.
2. Predicting where potholes are
This assumes a tree search, and one that is selective in the moves it examines. Typically the evaluation function not only delivers final evaluations but is also used to guide the search. You should have another secondary means of move selection. This comes under "plausibility analysis", which will be discussed in a later article, and this provides a second opinion of which moves are to be examined. This second opinion is a safeguard, as it will probably not share the same flaw as the evaluation function.
3. Detecting potholes during search
Evaluation anomalies can reveal themselves in the search. If the search tracks evaluation changes, it can spot when an evaluation apparently dips between moves. This can be recorded, so that in future the move that caused the dip can be flagged as a pothole, so that at future times the search will know that the move assessment will seem worse than it really is.
Conclusion
Constructing evaluation functions is both an art and a science. Getting it right requires experience and good judgement, backed-up with good engineering practice. A key necessity is careful testing of your evaluation function. Do not leave it for the tree search to expose this, as the defective evaluation will be hard to expose by trying to assess sub-optimal moves selected by search.
Hill-climbing has a good evaluation partner in the attractive and super-fast "piece position tables", which avoids potholes above. However this is its own important technique and will be discussed in a future article.http://www.aifactory.co.uk/newsletter/2005_03_hill-climbing.htm
Monday, April 14, 2014
Tower of hannoi recursive code in C
/*
* C program for Tower of Hanoi using Recursion
*/
#include <stdio.h>
void towers(int, char, char, char);
int main()
{
int num;
printf("Enter the number of disks : ");
scanf("%d", &num);
printf("The sequence of moves involved in the Tower of Hanoi are :\n");
towers(num, 'A', 'C', 'B');
return 0;
}
void towers(int num, char frompeg, char topeg, char auxpeg)
{
if (num == 1)
{
printf("\n Move disk 1 from peg %c to peg %c", frompeg, topeg);
return;
}
towers(num - 1, frompeg, auxpeg, topeg);
printf("\n Move disk %d from peg %c to peg %c", num, frompeg, topeg);
towers(num - 1, auxpeg, topeg, frompeg);
}
* C program for Tower of Hanoi using Recursion
*/
#include <stdio.h>
void towers(int, char, char, char);
int main()
{
int num;
printf("Enter the number of disks : ");
scanf("%d", &num);
printf("The sequence of moves involved in the Tower of Hanoi are :\n");
towers(num, 'A', 'C', 'B');
return 0;
}
void towers(int num, char frompeg, char topeg, char auxpeg)
{
if (num == 1)
{
printf("\n Move disk 1 from peg %c to peg %c", frompeg, topeg);
return;
}
towers(num - 1, frompeg, auxpeg, topeg);
printf("\n Move disk %d from peg %c to peg %c", num, frompeg, topeg);
towers(num - 1, auxpeg, topeg, frompeg);
}
Monday, April 7, 2014
interesting
http://en.wikipedia.org/wiki/Tower_of_Hanoi
http://www.mathsisfun.com/games/towerofhanoi.html
http://www.mathcs.emory.edu/~cheung/Courses/170/Syllabus/13/hanoi.html
Recursive code in c
/*
* C program for Tower of Hanoi using Recursion
*/
#include <stdio.h>
void towers(int, char, char, char);
int main()
{
int num;
printf("Enter the number of disks : ");
scanf("%d", &num);
printf("The sequence of moves involved in the Tower of Hanoi are :\n");
towers(num, 'A', 'C', 'B');
return 0;
}
void towers(int num, char frompeg, char topeg, char auxpeg)
{
if (num == 1)
{
printf("\n Move disk 1 from peg %c to peg %c", frompeg, topeg);
return;
}
towers(num - 1, frompeg, auxpeg, topeg);
printf("\n Move disk %d from peg %c to peg %c", num, frompeg, topeg);
towers(num - 1, auxpeg, topeg, frompeg);
}
http://www.mathsisfun.com/games/towerofhanoi.html
http://www.mathcs.emory.edu/~cheung/Courses/170/Syllabus/13/hanoi.html
Recursive code in c
/*
* C program for Tower of Hanoi using Recursion
*/
#include <stdio.h>
void towers(int, char, char, char);
int main()
{
int num;
printf("Enter the number of disks : ");
scanf("%d", &num);
printf("The sequence of moves involved in the Tower of Hanoi are :\n");
towers(num, 'A', 'C', 'B');
return 0;
}
void towers(int num, char frompeg, char topeg, char auxpeg)
{
if (num == 1)
{
printf("\n Move disk 1 from peg %c to peg %c", frompeg, topeg);
return;
}
towers(num - 1, frompeg, auxpeg, topeg);
printf("\n Move disk %d from peg %c to peg %c", num, frompeg, topeg);
towers(num - 1, auxpeg, topeg, frompeg);
}
Saturday, March 29, 2014
Wednesday, March 26, 2014
breadth first in prolog
PROLOG
%%%%%%% Breadth first search algorithm%%%%%%%%
%%%
%%% This is one of the example programs from the textbook:
%%%
%%% Artificial Intelligence:
%%% Structures and strategies for complex problem solving
%%%
%%% by George F. Luger and William A. Stubblefield
%%%
%%% Corrections by Christopher E. Davis (chris2d@cs.unm.edu)
%%%
%%% These programs are copyrighted by Benjamin/Cummings Publishers.
%%%
%%% We offer them for use, free of charge, for educational purposes only.
%%%
%%% Disclaimer: These programs are provided with no warranty whatsoever as to
%%% their correctness, reliability, or any other property. We have written
%%% them for specific educational purposes, and have made no effort
%%% to produce commercial quality computer programs. Please do not expect
%%% more of them then we have intended.
%%%
%%% This code has been tested with SWI-Prolog (Multi-threaded, Version 5.2.13)
%%% and appears to function as intended.
state_record(State, Parent, [State, Parent]).
go(Start, Goal) :-
empty_queue(Empty_open),
state_record(Start, nil, State),
add_to_queue(State, Empty_open, Open),
empty_set(Closed),
path(Open, Closed, Goal).
path(Open,_,_) :- empty_queue(Open),
write('graph searched, no solution found').
path(Open, Closed, Goal) :-
remove_from_queue(Next_record, Open, _),
state_record(State, _, Next_record),
State = Goal,
write('Solution path is: '), nl,
printsolution(Next_record, Closed).
path(Open, Closed, Goal) :-
remove_from_queue(Next_record, Open, Rest_of_open),
(bagof(Child, moves(Next_record, Open, Closed, Child), Children);Children = []),
add_list_to_queue(Children, Rest_of_open, New_open),
add_to_set(Next_record, Closed, New_closed),
path(New_open, New_closed, Goal),!.
moves(State_record, Open, Closed, Child_record) :-
state_record(State, _, State_record),
mov(State, Next),
% not (unsafe(Next)),
state_record(Next, _, Test),
not(member_queue(Test, Open)),
not(member_set(Test, Closed)),
state_record(Next, State, Child_record).
printsolution(State_record, _):-
state_record(State,nil, State_record),
write(State), nl.
printsolution(State_record, Closed) :-
state_record(State, Parent, State_record),
state_record(Parent, _, Parent_record),
member(Parent_record, Closed),
printsolution(Parent_record, Closed),
write(State), nl.
add_list_to_queue([], Queue, Queue).
add_list_to_queue([H|T], Queue, New_queue) :-
add_to_queue(H, Queue, Temp_queue),
add_list_to_queue(T, Temp_queue, New_queue).
http://www.cs.unm.edu/~luger/ai-final/code/PROLOG.breadth.html
Wednesday, March 19, 2014
Installing SWI-Prolog Editor
http://lakk.bildung.hessen.de/netzwerk/faecher/informatik/swiprolog/indexe.html
Saturday, March 15, 2014
intro to logic
http://veritasdomain.wordpress.com/2007/03/30/lectures-on-introduction-to-logic-philosophy/
http://www.slideshare.net/gracia2k3/logic-ppt
http://www.slideshare.net/gracia2k3/logic-ppt
Thursday, March 13, 2014
Prolog - Tutorials
http://www.swi-prolog.org/
http://www.gprolog.org/
http://en.wikibooks.org/wiki/Prolog
http://www.doc.gold.ac.uk/~mas02gw/prolog_tutorial/prologpages/
https://www.csupomona.edu/~jrfisher/www/prolog_tutorial/intro.html
http://www.gprolog.org/
http://en.wikibooks.org/wiki/Prolog
http://www.doc.gold.ac.uk/~mas02gw/prolog_tutorial/prologpages/
https://www.csupomona.edu/~jrfisher/www/prolog_tutorial/intro.html
Problem Solving in Prolog
Reference: Bratko chapter 12
Problem solving has traditionally been one of the key areas of concern for
Artificial Intelligence. Below, we present a common problem and demonstrate a
simple solution.

A
graph may be represented by a set of edge predicates and a list of vertices.
 Depth first search begins by diving down as quickly as possible to the leaf
nodes of the tree. Traversal can be done by:
Depth first search begins by diving down as quickly as possible to the leaf
nodes of the tree. Traversal can be done by:
CRICOS Provider Code No. 00098G
Copyright (C) Bill Wilson, 2002, except where another source is acknowledged.
http://www.cse.unsw.edu.au/~billw/cs9414/notes/mandc/mandc.html
| Aim: |
| To illustrate search in AI using a fairly well-known example problem. We also briefly introduce a number of different methods for exploring a state space (or any other graph to be searched). |
| Keywords: breadth first search, depth first search, edge in a graph, goal state, graph, directed acyclic graphs, trees, binary trees, adjacency matrices, graph search algorithms, initial state, node, operator, state, initial state, goal state, path, search, vertex |
| Plan: |
|
Missionaries and Cannibals
- There are three missionaries and three cannibals on the left bank of a river.
- They wish to cross over to the right bank using a boat that can only carry two at a time.
- The number of cannibals on either bank must never exceed the number of missionaries on the same bank, otherwise the missionaries will become the cannibals' dinner!
- Plan a sequence of crossings that will take everyone safely accross.
- states
- which are snapshots of the world and
- operators
- which transform one state into another
Graph Representation
edge(1, 5). edge(1, 7). edge(2, 1). edge(2, 7). edge(3, 1). edge(3, 6). edge(4, 3). edge(4, 5). edge(5, 8). edge(6, 4). edge(6, 5). edge(7, 5). edge(8, 6). edge(8, 7). vertices([1, 2, 3, 4, 5, 6, 7, 8]).
Finding a path
- Write a program to find path from one node to another.
- Must avoid cycles (i.e. going around in circle).
- A template for the clause is:
path(Start, Finish, Visited, Path).
- Start
- is the name of the starting node
- Finish
- is the name of the finishing node
- Visited
- is the list of nodes already visited.
- Path
- is the list of nodes on the path, including Start and Finish.
The Path Program
- The search for a path terminates when we have nowhere to go.
path(Node, Node, _, [Node]).
- A path from Start to Finish starts with a node, X, connected to Start followed by a path from X to Finish.
path(Start, Finish, Visited, [Start | Path]) :- edge(Start, X), not(member(X, Visited)), path(X, Finish, [X | Visited], Path).Here is an example of the path algorithm in action.
Representing the state
Now we return to the problem of representing the missionaries anc cannibals problem:- A state is one "snapshot" in time.
- For this problem, the only information we need to fully characterise the
state is:
- the number of missionaries on the left bank,
- the number of cannibals on the left bank,
- the side the boat is on.
- In Prolog, the state can be represented by a 3-arity term,
state(Missionaries, Cannibals, Side)
Representing the Solution
- The solution consists of a list of moves, e.g.
[move(1, 1, right), move(2, 0, left)]
- We take this to mean that 1 missionary and 1 cannibal moved to the right bank, then 2 missinaries moved to the left bank.
- Like the graph search problem, we must avoid returning to a state we have visited before.
- The visited list will have the form:
[MostRecent_State | ListOfPreviousStates]
Overview of Solution
- We follow a simple graph search procedure:
- Start from an initial state
- Find a neighbouring state
- Check that the new state has not been visited before
- Find a path from the neighbour to the goal.
state(0, 0, right).
Top-level Prolog Code
% mandc(CurrentState, Visited, Path) mandc(state(0, 0, right), _, []). mandc(CurrentState, Visited, [Move | RestOfMoves]) :- newstate(CurrentState, NextState), not(member(NextState, Visited)), make_move(CurrentState, NextState, Move), mandc(NextState, [NextState | Visited], RestOfMoves]). make_move(state(M1, C1, left), state(M2, C2, right), move(M, C, right)) :- M is M1 - M2, C is C1 - C2. make_move(state(M1, C1, right), state(M2, C2, left), move(M, C, left)) :- M is M2 - M1, C is C2 - C1.
Possible Moves
- A move is characterised by the number of missionaries and the number of cannibals taken in the boat at one time.
- Since the boat can carry no more than two people at once, the only possible combinations are:
carry(2, 0). carry(1, 0). carry(1, 1). carry(0, 1). carry(0, 2).
- where carry(M, C) means the boat will carry M missionaries and C cannibals on one trip.
Feasible Moves
- Once we have found a possible move, we have to confirm that it is feasible.
- I.e. it is not feasible to move more missionaries or more cannibals than are present on one bank.
- When the state is state(M1, C1, left) and we try carry(M, C) then
M <= M1 and C <= C1
- must be true.
- When the state is state(M1, C1, right) and we try carry(M, C) then
M + M1 <= 3 and C + C1 <= 3
- must be true.
Legal Moves
- Once we have found a feasible move, we must check that is legal.
- I.e. no missionaries must be eaten.
legal(X, X). legal(3, X). legal(0, X).
- The only safe combinations are when there are equal numbers of missionaries and cannibals or all the missionaries are on one side.
Generating the next state
newstate(state(M1, C1, left), state(M2, C2, right)) :- carry(M, C), M <= M1, C <= C1, M2 is M1 - M, C2 is C1 - C, legal(M2, C2). newstate(state(M1, C1, right), state(M2, C2, left)) :- carry(M, C), M2 is M1 + M, C2 is C1 + C, M2 <= 3, C2 <= 3, legal(M2, C2).The complete code, with instructions for use, is available at http://www.cse.unsw.edu.au/~billw/cs9414/notes/mandc/mandc.pro
Methods of Search
In the preceding example, the state space is explored in an order determined by Prolog. In some situations, it might be necessary to alter that order of search in order to make search more efficient. To see what this might mean, here are two alternative methods of searching a tree.
Depth first search begins by diving down as quickly as possible to the leaf
nodes of the tree. Traversal can be done by:- visiting the node first, then its children (pre-order traversal):
a b d h e i j c f k g - visiting the children first, then the node (post-order traversal):
h d i j e b k f g c a - visiting some of the children, then the node, then the other children (in-order traversal)
h d b i e j a f k c g
| Summary: Problem Solving and Search in AI |
|
We introduced the concepts of states and operators and gave a
graph traversal algorithm that can be used as a problem solving tool.
We applied this to solve the "missionaries and cannibals"
problem. We also outlined depth-first search, breadth-first search, and alluded to the existence of a range of other search methods. |
Copyright (C) Bill Wilson, 2002, except where another source is acknowledged.
http://www.cse.unsw.edu.au/~billw/cs9414/notes/mandc/mandc.html
Monday, March 10, 2014
Glossary
- Actuator – something with effects the environment around it
- Agent – anything that can be viewed as perceiving its environment through sensors and acting upon it.
- Agent function – the mathematical way of describing an agents behavior
- Agent program – the agents dedicated programming (implements the agent function)
- Architecture – the layout of the agent
- Artificial intelligence – man-made intelligence.
- Autonomy – how little the agent relies on prior knowledge
- Condition-action rule – a rule which tell the agent how to act given a condition
- Critic – tells the learning element how well the agent is doing
- Deterministic – an environment in which the next state is solely determined by the current state and the action executed by the agent
- Dynamic – the environment can change while the agent is deliberating
- Effecter – something with effects the environment around it
- Environment – the landscape upon which the agent works
- Episodic – the choice of action taken by the agent depends only on the current state
- Goal – what the agent hopes to achieve
- Goal based agent – an agent which chooses an action form a list of actions which helps the agent complete its goals
- Internal state – the previous state of the world held inside the agents’ memory
- Learning – improving techniques through previous experiences
- Learning element – makes improvements to the performance element
- Model based agent – an agent which uses the current state it can see and the internal state to call a condition-action rule.
- Multi-agent – Many agents in one environment communicating together affecting each others decisions
- Observabillity – how much of an agents environment can be seen at any given instant
- Omniscience – when an agent knows an actual outcome of an action and acts accordingly
- Percepts – an agencies perceptual input at any given instant
- Percept sequence – the complete history of everything perceived by the agent
- Performance element – responsible for choosing external actions
- Performance measure – the criterion for an agent’s behavior
- Problem generator – introduces the performance element to new actions
- Rationality – the ideal concept of intelligence.
- Semi-dynamic – if the agents’ performance score can change while the agent is deliberating
- Sensors – something that can describe the environment around it
- Sequential – The current decision chosen by the agent affects all future decisions
- Simple reflex agent – an agent which takes the current situation and acts upon it if it has the correct condition – action rule
- Software agent – an agent whose environment is held in software
- Static – the environment doesn’t change while the agent is deliberating
Applications of agents
Automated driving
This is a goal based, utility based agent. Cameras are
used to gain positions of car, the edges of lanes and the position of
the goals. The car can speed up, slow down, change lanes, turn, park,
pull away…….

In the scenario above car A can do any of the tasks but the ones which stand out as the ones that will have the highest outputs of the utility function are, change lanes or stay behind car B.
A.L.I.C.E. – a chat bot
 A.L.I.C.E.
is an online chat bot, A.L.I.C.E. is a learning reflex agent, and
given certain keywords the bot has a predetermined response but if the
bot doesn’t know how to reply properly then the bot will ask a question
which will help the bot learn how to answer the question in the
future. This eventually builds up a large amount of condition-action
rules. The more people use A.L.I.C.E. the better A.L.I.C.E. will get at
having a fluid conversation.
A.L.I.C.E.
is an online chat bot, A.L.I.C.E. is a learning reflex agent, and
given certain keywords the bot has a predetermined response but if the
bot doesn’t know how to reply properly then the bot will ask a question
which will help the bot learn how to answer the question in the
future. This eventually builds up a large amount of condition-action
rules. The more people use A.L.I.C.E. the better A.L.I.C.E. will get at
having a fluid conversation.The software agents group
 This is a section of MIT that researches into software agents.
This is a section of MIT that researches into software agents.IBM - Intelligent Agents Project
http://www.doc.ic.ac.uk/project/examples/2005/163/g0516334/app.html
Types of Environments
- Deterministic and non-deterministic
An environment is deterministic if the next state of the environment is solely determined by the current state of the environment and the actions selected by the agents. An inaccessible environment might appear to be non-deterministic since the agent has no way of sensing part of the environment and the result of its actions on it. We have to take into consideration the point of view of the agent when determining whether an environment is deterministic or not since the agent might have limited perception capabilities.
- Episodic and non-episodic
In an episodic environment, the agent's experience is divided into episodes which consist of a percept sequence and an action. Since episodes are independent of one another and the agent doesn't need to know the effect of its actions.
- Static and dynamic
An environment is dynamic if it changes while an agent is in the process of responding to a percept sequence. It is static if it does not change while the agent is deciding on an action i.e the agent does not to keep in touch with time. An environment is semidynamic if it does not change with timebut he agent's performace score does.
- Discrete and continuous
If the number of percepts and actions in the environment is limited and distinct then the environment is said to be discrete.eg A chess board.

Sunday, March 9, 2014
Tuesday, March 4, 2014
Two Major Challenges with Speech-Recognition Technology

Speech is still a relatively new interface. Technology is finally starting to catch up to the dreams that we've had since the invention of the computer itself: dreams of having natural conversations with computers—something portrayed in countless science fiction movies, TV shows, and books.
But from a UX standpoint, what does "natural" even mean?
The most popular conception of a natural conversation with a computer is one in which the user can say anything they want and the computer will understand and respond appropriately. In commercials, Appleadvertises Siri as a personal assistant that you can seemingly say anything to. This, however, is far from reality.
It’s a speech designer's job to make it seem as if users can say anything, when that’s not actually the case. Designers must develop ways to shape and constrain a user's interactions with their device. Users must be trained to communicate in an understandable manner that doesn’t make them feel like they’re tailoring the way they speak to their devices.
Users must also be made aware of what the device can do to prevent them from making errors and how to harness the complete power of the device: the two biggest challenges designing for user experience in speech recognition technology.
Feature Discovery
This is by far the hardest part of speech interface design. Speech recognition is still very new so we simply cannot recognize and do everything. Even other humans sometimes misunderstand or misinterpret what someone is saying. On top of that, people rarely look through user manuals or research everything a device can do.
Designers need to find ways to educate users about what they can do as they are interacting with devices. With touch interfaces this can be achieved through well-named buttons and high level categorization. Many speech interfaces do not have the luxury of these visual queues.
The most obvious way that people train one another is through explicit instruction. Teachers spend a lot of time lecturing their students. Parents explain to their kids that they should treat others the way they wish to be treated. This can be one way for devices to train users, but is potentially time-consuming and frustrating for experienced users. As interface designers we must find more ways to help users train themselves through self-discovery.
Another way that we teach one another is through leading by example. We don't teach a newborn to speak their first words by telling them how to shape their mouth and where to place their tongue. We speak in front of them and they experiment on their own to mimic the sounds they hear.
Nobody teaches someone to use a revolving door: we see someone else use it and copy them. Are there any opportunities for the device to lead the way in an interaction? Maybe two different virtual actors communicating for a user to observe. This method could end up being verbose but, if done well, could also be very successful considering our brains are wired to learn this way.
Bottom line: if the user can't figure out what they can do with the device they may never unlock its power, negating all of the work designers put into it.
Phrasing
People have developed many ways to express ideas, and even many ways to express the same idea. Synonyms and ambiguities are incredibly challenging elements of speech recognition from a technical point of view, forcing developers to choose between accuracy and performance. If we can design a UX that reduces ambiguity and the number of ways to phrase an idea, the system can be tuned to perform much better. If the device uses consistent phrasing the user will tend towards using the same phrasing in the future.
People frequently repeat what another person has said, with very slight variation, in order to clarify an idea. This can often be a mechanism for helping someone learn to express an idea better.
A mother teaching the difference between "can" and "may" might go like this:
"Mommy, can I have soda?"
"May you have soda?"
Designers standardizing terminology:
"When the user drags their finger quickly to the left the page should move to the next page on the right."
"Ok, so a swipe left transitions to the right page?"
This means that if we have a device that can tell time, it can be listening for the following phrases.
- "What time is it?"
- "What hour is it?"
- "How late is it?"
The device can always reply "The time is five thirty-two," queuing the user to use “time” instead of “hour” or “late.” Developers can then concentrate on making the "What time is it?" phrase work better.
Lastly, another idea for training the user's phrasing is to use non-verbal positive and/or negative feedback.People use body language to indicate if they understand what someone else is saying. They will often nod along if they understand or they may have a puzzled expression if they don't.
It would be great if we could develop a similar system for speech recognition devices. A positive tone of voice could indicate that the device understands the user very well, providing a subtle hint that they should continue to use similar phrasing. We may also flash the screen or vibrate the device to signify a positive or negative response.
Phrasing may be just an intermediate step until technology improves, but training the user to use more predictable phrasing will always improve the experience.
The Even Bigger Problem
The key to solving these problems is feedback, and here is the true difficulty: how can the device provide unobtrusive and concise feedback that helps shape the new user without frustrating the experienced one? To make this even more difficult, speech interfaces are often used in circumstances where the user cannot be looking at the device, so we can’t rely on existing paradigms of visual feedback.
There is hope, however. People are expert auditory communicators: we all do it every day. There are many things we can learn by studying how we speak with one another. What other tools can we learn and utilize to make everyone an expert with speech interfaces?
https://uxmag.com/articles/two-major-challenges-with-speech-recognition-technology
https://uxmag.com/articles/two-major-challenges-with-speech-recognition-technology
Monday, March 3, 2014
Fraud Detection Using Neural Networks and Sentinel
Fraud Detection Using Neural Networks and Sentinel Solutions (Smartsoft)
Fraud detection is a continuously evolving discipline and requires a tool that is intelligent enough to adapt to criminals strategies and ever changing tactics to commit fraud. Despite the best efforts of the FBI and other law enforcement organizations, fraud still costs American companies an overwhelming $400 billion (reference) each year. With the relatively recent growth of the Internet into a global economic force, credit card fraud has become more prevalent.
It is in a company and card issuer’s interest to prevent fraud or, failing this, to detect fraud as soon as possible. Otherwise consumer trust in both the card and the company decreases and revenue is lost, in addition to the direct losses made through fraudulent sales.
How do Neural Networks Help with Fraud Detection?
The inherit nature of neural networks is the ability to learn is being able to capture and represent complex input/output relationships. The motivation for the development of neural network technology stemmed from the desire to develop an artificial system that could perform "intelligent" tasks similar to those performed by the human brain. Neural networks resemble the human brain in the following two ways:
- A neural network acquires knowledge through learning.
- A neural network's knowledge is stored within inter-neuron connection strengths known as synaptic weights. The true power and advantage of neural networks lies in their ability to represent both linear and non-linear relationships and in their ability to learn these relationships directly from the data being modeled. Traditional linear models are simply inadequate when it comes to modeling data that contains non-linear characteristics.
 |  |
What is Sentinel?
Sentinel is a complete solution designed to prevent, detect, analyze and follow up banking fraud in any entity or corporation in the financial business. Specific fraud detection solutions may include:
- Credit
- Debit
- ATM
With Sentinel your company can monitor the activities of accounts, cardholders and merchants by using a robust and powerful technology based on rules, parameters and indicators. In other words, you can obtain immediate results from the moment you install the software.
Sentinel allows you to:
- Process data from any origin, whether it comes from transactions, merchants or cardholders.
- Monitor issuer, acquirer or banking activities.
- Examine information by strategic business units such as countries, regions, banks, etc.
- Analyze data from a managerial perspective, through a technology known as “Business Intelligence.”
- Evaluate the performance of the rules created in the system and the profit generated by them.
- Minimize risk and loss due to banking fraud.
What is Neural Fraud Management Systems (NFMS)? The Neural Fraud Management System is a completely automated and state-of-the-art integrated system of neural networks, Fraud Detection Engine, Automatic Modeling System (AMS), supervised clustering, and system retune.
Combined with Sentinel the Neural Fraud Management System (NFMS) can automatically scale the relative importance of fraud to non-fraud, group symbols to reduce dimensionality, and evolve over time to detect new patterns and trend types in frauds.
By adding the intelligence of neural network technology to an already successful rule-based system, you can increase the detection of legitimate fraud transactions up to 80% with as low as 1% false detections or less!
How does NFMS work?

- The Neural Networks are completely adaptive able to learn from patterns of legitimate behavior and adapting to the evolving of behavior of normal transactions and patterns of fraud transactions and adapting to the evolving of the behavior of fraud transactions. The recall process of the Neural Networks is extremely fast and can make decisions in real time.
- Supervised Clustering uses a mix of traditional clustering and multi-dimensional histogram analysis with a discrete metric. The process is very fast and can make decisions in real time.
- Statistical Analysis ranks the most important features based on the joint distribution per transaction patterns. In addition, it finds the optimal subset of features and symbols with maximum information and minimum redundancy.
- The Fraud Detection Engine can apply the generated model by AMS on input data stream and output the detection results by specified model: Neural Networks, Clustering, and Combined. The Fraud Detection Engine supports both Windows and UNIX platforms.
- Retuning the basic model created by AMS to adapt to the recent trend of both the legitimate behavior and fraud behavior and update the model for Fraud Detection Engine.
- The Automatic Modeling System (AMS) chooses the important inputs and symbols, train and create clustering and neural network models.
Advantages
- Significantly reduces losses due to fraud.
- Identify new fraud methods to reduce fraud losses and minimize false positives.
- It can work in real time, online or batch modes.
- Reinforce customer trust.
- Improve operational efficiencies.
- The system could develop better models by customizing the model to the Banks unique environment.
- Build and update models as the new business requirements or changes in the environment.
- The system gives you the flexibility to easily incorporate data from many sources to the neural models.
- You have the ability to build your own custom model, in house, without being an expert in AI programming. The final user could use the wizard-based interface to create new models or change the existing ones.
- Combine multiple Artificial Intelligence technologies to identify suspicious activity (clustering, neural networks, rules, profiles).
- It provides all life cycle to avoid fraud, including the stages: monitoring, preventing, detecting, registering, learning, self building.
- Boosts analyst productivity and improves effectiveness of fraud operations.
- Non intrusive implementation and easy to integrate with standard protocols: XML, SOAP / Web Services. Additionally NFMS provides API to enable an easy integration in the Bank environment if necessary.
Success Stories
- León Bank in Dominican Republic had reduced fraud by 60% in the first 3-months of the utilization of the system.
- Guayaqyuil Bank in Ecuador had 100% detection of fraud cases in the first month.
- Credit Card Issuer Bank* saved over $3,000,000 (US Dollars) in the first 10-months of 2003 with a fraud reduction of 30% from the prior year. (Full Text PDF)
http://www.nd.com/resources/smartsoft.html
Sunday, March 2, 2014
Artificial Intelligence in Logistics planning

Scientists at Universidad Carlos III in Madrid have presented a new technique based on artificial intelligence that can automatically create plans, allowing problems to be solved with much greater speed than current methods provide when resources are limited. This method can be applied in sectors such as logistics, autonomous control of robots, fire extinguishing and online learning.
The researchers have developed a new methodology to solve automated planning problems, an area of AI, especially when there are more objectives than it is possible to achieve in the available time. The idea is to get the system to find, on its own, an ordered sequence of actions that will allow objectives to be reached (in a final stage) given the initial situation and available resources. For example, given a group of trucks and goods, these techniques can use automatic planning to optimize the routes and means of transport, based on timetables and products. The methodology presented by these scientists would, in this case, allow the users to create plans in a situation in which not all the packages can be delivered, as would occur when the time that is needed to perform the task is greater than the time that is available, because of the inadequacy of the available resources. In this case, the system would attempt to find a plan by which the greatest number of goods possible could be delivered, thus minimizing the cost.
The new methodology that these scientists propose allows solutions to be found that are equivalent to or better than those provided by the other existing techniques, in addition to doing so much faster, when there are limited resources that can be used. "With regard to time, our technique is three to ten times faster, and with regard to quality, our solutions offer similar quality to that obtained by the best technique that is currently available", states one of the researchers, Ángel García Olaya, of the PLG group (Planning and Learning Research Group) of UC3M's Computer Science Department. "Now – he points out – we are making modifications that we hope will allow us to give still greater quality to our solutions". This study has been presented at the most recent Conferencia Española para la Inteligencia Artificial (CAEPIA – Spanish Conference on Artificial Intelligence) in Tenerife, where it received the award for the best article. In addition, it has recently been published in Lecture Notes in Computer Science by Springer. This research at UC3M has received funding from the Autonomous Community of Madrid and the Ministry of Science and Innovation.
This new methodology can be applied in any sector in which is makes sense to implement automatic planning, as is already done in the cases of extinguishing fires, autonomous control of robots, on-line learning, logistics, etc. In this last field, in fact, these researchers have already carried out a project with Acciona for managing their logistics division; it was subsidized by the Ministry of Industry, Tourism and Commerce. To be specific, they created a system of automatic planning for multimodal transport of goods. The data that was provided to the system included the position of the trucks, as well as the schedules of the transport ships and trains, together with the characteristics of the clients' orders (situation of containers, route, type of merchandise). With this information, the system first decided which truck and container should carry out each part of the service, to then calculate the route to be taken, the order in which the items would be delivered and, if necessary, to change the method of transport (truck, train and/or boat).
"What very often happens in real situations is that there is no plan that can reach all of the objectives due to the limitations of one resource, such as time, money, fuel, battery... and this is where the methodology proposed in the article can be used", explains Professor Ángel García Olaya. The researchers have tested it in a series of realms that simulate real situations and that occur frequently in the field of planning; it has already been integrated into an architecture for the autonomous control of robots that the group is working on. In fact, NASA has already used automatic planning for the autonomous control of their rovers, Spirit and Opportunity, which traveled to Mars a few years ago. In that case, they used a mixed initiative system in which the rovers' operators used a planner to create the plans (movements, sample taking, photos, etc.) for the two automated vehicles. The planner took all of the operating restrictions into account and created a plan that could be modified by the operators. Later the plan, which had been conveniently checked to avoid any inconsistency, was transmitted to the rovers so that they could execute it. Currently, the PLG group is applying the techniques developed in a project carried out with the European Space Agency (ESA) on the planning of observation operations in space.
http://phys.org/news/2012-01-artificial-intelligence-technique-tasks-resources.html
Subscribe to:
Posts (Atom)